第四部分 标准库扩展和修改
这一部分介绍了用C++17对现有库组件的扩展和修改。
21类型特征扩展
关于类型特征(标准类型函数),C++17扩展了使用它们的一般能力,并且 引入了一些新的类型特征。
21.1 类型特征的Suffix _v
从C++17开始,你可以对所有产生数值的类型特征使用后缀_v(因为你可以对所有产生类型的类型特征使用后缀_t)。例如,对于任何类型的T,而不是
std::is_const<T>::value
你现在可以写:
std::is_const_v<T> // since C++17
这适用于所有类型特征。其方法是,为每个标准类型特征定义一个相应的 变量模板。比如说:
namespace std {
template<typename T>
constexpr bool is_const_v = is_const<T>::value;
}
通常,这有助于制定布尔条件,你可以在运行时使用:
if (std::is_signed_v<char>) {
...
}
但由于类型特征是在编译时评估的,所以你可以在编译时使用编译时的结果,即compile-time if:
if constexpr (std::is_signed_v<char>) {
...
}
或在实例化模板时:
// C<T>类的主要模板
template<typename T, bool = std::is_pointer_v<T>>
class C {
...
};
// 指针类型的部分特殊化。
template<typename T>
class C<T, true> {
...
};
在这里,以C类为例,它为指针类型提供了一个特殊的实现。 但是如果类型特征产生一个非布尔值,后缀_v也可以使用,比如std::extreme<>。它产生的是一个原始数组的维度大小:
int a[5][7];
std::cout << std::extent_v<decltype(a)> << '\n'; // prints 5
std::cout << std::extent_v<decltype(a),1> << '\n'; // prints 7
21.2 新类型特征
C++17 引入了几个新的类型特征。 此外, is_literal_type<> 和 result_of<> 自 C++17 起已弃用。 正在建设中的详细说明
is_aggregate<>
std::is_aggregate 评估 T 是否为聚合类型:
template<typename T>
struct D : std::string, std::complex<T> {
std::string data;
};
D<float> s{{"hello"}, {4.5,6.7}, "world"}; // OK since C++17
std::cout << std::is_aggregate<decltype(s)>::value; // outputs: 1 (true)
21.3 std::bool_constant< >。
如果特征产生布尔值,它们现在使用别名模板 bool_constant<>:
namespace std {
template<bool B>
using bool_constant = integral_constant<bool, B>; // since C++17
using true_type = bool_constant<true>;
using false_type = bool_constant<false>;
}
| 特征 | 作用 |
|---|---|
| is_aggregate | 是聚合类型 |
| has_unique_object_representations | 任何两个具有相同值的对象在内存中具有相同的表示 |
| is_invocable<T,Args…> | 可用作 Args 的可调用对象… |
| is_nothrow_invocable<T,Args…> | 可用作 Args… 的可调用对象…无需抛出 |
| is_invocable_r<RT,T,Args…> | 可用作 Args 的可调用… 返回 RT |
| is_nothrow_invocable_r<RT,T,Args…> | 可用作 Args 的可调用对象…返回 RT 而不抛出 |
| invoke_result<T,Args…> | 如果用作 Args 的可调用结果类型… |
| is_swappable | is_swappable 可以为此类型调用 swap() |
| is_nothrow_swappable | 可以为此类型调用 swap() 并且该操作不能抛出 |
| is_swappable_with<T,T2> | 可以为这两种具有特定值类别的类型调用 swap() |
| is_nothrow_swappable_with<T,T2> | 可以为这两种具有特定值类别的类型调用 swap() 并且该操作不能抛出 |
| conjunction<B…> | 逻辑和布尔特征 B… |
| disjunction<B… > | 逻辑或布尔特征 B… |
| negation | 逻辑不用于布尔特征 B |
在C++17之前,std::true_type和std::false_type分别被直接定义为std::integral_constant<bool,true>和std::integral_constant<bool,false>的别名定义。 尽管如此,如果一个特定的属性适用,布尔特性通常继承自std::true_type,如果不适用则继承自std::false_type。比如说:
// 主模板:通常 T 不是 void 类型
template<typename T>
struct IsVoid : std::false_type {
};
// void 类型的特化:
template<>
struct IsVoid<void> : std::true_type {
};
但是现在你可以通过派生自bool_constant<>来定义你自己的类型特质,如果你能够把相应的编译时表达式表述为布尔条件的话。比如说:
template<typename T>
struct IsLargerThanInt
: std::bool_constant<(sizeof(T) > sizeof(int))> {
}
这样你就可以使用这样一个特性,根据一个类型是否大于int来进行编译:
template<typename T>
void foo(T x)
{
if constexpr(IsLargerThanInt<T>::value) {
...
}
}
通过添加后缀_v的相应变量模板作为内联变量:
template<typename T>
inline static constexpr auto IsLargerThanInt_v = IsLargerThanInt<T>::value;
你也可以缩短该特性的用法,如下所示:
template<typename T>
void foo(T x)
{
if constexpr(IsLargerThanInt_v<T>) {
...
}
}
作为另一个例子,我们可以定义一个特质,检查一个类型T的移动构造函数是否保证不抛出,大致如下:
template<typename T>
struct IsNothrowMoveConstructibleT
: std::bool_constant<noexcept(T(std::declval<T>()))> {
};
21.4 std::void_t< >
在C++17中,一个小小的,但令人难以置信的有用的定义类型特征的辅助工具被标准化了:std::void_t<>。 它被简单地定义如下:
namespace std {
template<typename...> using void_t = void;
}
也就是说,它对任何模板参数的变量列表都会产生无效。这很有帮助,我们只想在参数列表中处理类型。 主要的应用是在定义新的类型特征时检查条件的能力。下面的例子演示了这个帮助器的应用:
#include <utility> // 对于declval<>来说
#include <type_traits> // 为true_type,false_type,和void_t
// 主模板:
template<typename, typename = std::void_t<>>
struct HasVarious : std::false_type {
};
// 部分专业(可能会被SFINAE所取代):
template<typename T>
struct HasVarious<T, std::void_t<decltype(std::declval<T>().begin()),
typename T::difference_type,
typename T::iterator>>
: std::true_type {
};
在这里,我们定义了一个新的类型特质HasVariousT<>,它检查三件事。
-
该类型是否有一个成员函数begin()?
-
该类型是否有一个类型成员 difference_type?
-
该类型是否有一个类型成员迭代器? 只有当所有相应的表达式都对一个类型T有效时,才会使用部分专业化。那么它就比主模板更具体,而且由于我们从std::true_type派生出来,对这个特征的值进行检查会得到true。
if constexpr (HasVarious<T>::value) { ... }
如果任何一个表达式的结果是无效的代码(即T没有begin(),或者没有类型成员difference_type,或者没有类型成员iterator),部分专业化就会被SFINAE’d掉,这意味着由于替换失败不是错误的规则,它被忽略。然后,只有主模板是可用的,它派生自std::false_type,所以对这个特质的值进行检查会产生false。 同样地,你可以使用std::void_t轻松地定义其他特质来检查一个或多个条件,其中一个成员或操作的存在/能力很重要。
21.5 后记
标准类型性状的变量模板最早是由Stephan T. Lavavej在2014年提出的 https://wg21.link/n3854。它们最终被采纳为图书馆基本原理TS的一部分 的一部分,由Alisdair Meredith在https://wg21.link/p0006r0。
类型特质std::is_aggregate<>是作为美国国家机构的评论引入的,用于C++17的标准化。C++17的标准化而引入的(见https://wg21.link/lwg2911)。
std::bool_constant<>是由袁志豪在https://wg21.link/n4334 中首次提出的。它们最终被采纳为袁志豪在https://wg21.link/n4389 中的提议。
std::void_t_<>是由Walter E. Brown在https://wg21.link/n3911 中提出的,被采用。建设中
22 并行STL算法
为了从现代多核架构中获益,C++17标准库引入了让STL标准算法使用多线程运行的能力,以并行处理不同的元素。
许多算法通过一个新的第一参数进行了扩展,以指定是否以及如何在并行线程中运行算法(当然,没有这个参数的老方法仍然被支持)。此外,还引入了一些专门支持并行处理的补充算法。
一个简单的计时器助手
在本章的例子中,有时我们需要一个定时器来测量算法的速度。为此,我们使用了一个简单的辅助类,它初始化了一个定时器,并提供了printDiff()来打印消耗的毫秒数并重新初始化定时器:
lib/timer.hpp
#ifndef TIMER_HPP
#define TIMER_HPP
#include <iostream>
#include <string>
#include <chrono>
/********************************************
* timer to print elapsed time
********************************************/
class Timer
{
private:
std::chrono::steady_clock::time_point last;
public:
Timer()
: la st{std::chrono::steady_clock::now()} {
}
void printDiff(const std::string& msg = "Timer diff: ") {
auto now{std::chrono::steady_clock::now()};
std::chrono::duration<double, std::milli> diff{now - last};
std::cout << msg << diff.count() << "ms\n";
last = std::chrono::steady_clock::now();
}
};
#endif // TIMER_HPP
22.1 使用并行算法
让我们从一些例子程序开始,展示让现有算法并行运行和使用新的并行算法的能力。
22.1.1 使用并行的for_each()
这是并行运行标准算法 for_each() 的第一个非常简单的示例:
lib/parforeach.cpp
#include <vector>
#include <iostream>
#include <algorithm>
#include <numeric>
#include <execution> // 对于执行策略
#include "timer.hpp"
int main()
{
int numElems = 1000;
struct Data {
double value; // 初始值
double sqrt; // 并行计算平方根
};
// 初始化没有平方根的 NumElems 值:
std::vector<Data> coll;
coll.reserve(numElems);
for (int i=0; i<numElems; ++i) {
coll.push_back(Data{i * 4.37, 0});
}
// 平方根的并行计算:
for_each(std::execution::par,
coll.begin(), coll.end(),
[](auto& val) {
val.sqrt = std::sqrt(val.value);
});
}
正如你所看到的,使用并行算法在原则上是非常容易的。
- 包括头文件。
- 按照你通常调用算法的方式来调用算法,并附加一个第一个参数,这个参数通常是简单的std::execution::par。
在这种情况下,我们使用标准算法for_each()来计算传递的向量coll中所有元素的成员值的平方根。由于额外的第一个参数std::execution::par,我们要求该算法以并行模式运行:
#include <algorithm>
#include <execution>
...
for_each(std::execution::par,
coll.begin(), coll.end(),
[](auto& val) {
val.sqrt = std::sqrt(val.value);
});
像往常一样,coll在这里可以是任何范围。但是请注意,所有的并行算法都要求迭代器至少是前向迭代器(我们在不同的线程中迭代相同的元素,如果迭代器不迭代相同的值,那就没有意义)。 算法并行运行的方式是具体实现的。当然,使用多线程也不一定更快,因为启动和处理多线程也需要时间。
性能优势
为了找到如何、是否以及何时值得并行运行这个算法,让我们把这个例子修改如下。
lib/parforeach.cpp
#include <vector>
#include <iostream>
#include <algorithm>
#include <numeric>
#include <execution> // for the execution policy
#include "timer.hpp"
int main()
{
int numElems = 1000;
struct Data {
double value; // 初始值
double sqrt; // 并行计算平方根
};
// 初始化没有平方根的 NumElems 值:
std::vector<Data> coll;
coll.reserve(numElems);
for (int i=0; i<numElems; ++i) {
coll.push_back(Data{i * 4.37, 0});
}
// 平方根的并行计算:
for_each(std::execution::par,
coll.begin(), coll.end(),
[](auto& val) {
val.sqrt = std::sqrt(val.value);
});
}
关键的修改是。
- 我们可以通过命令行传递我们操作的数值的多少。
- 我们使用类Timer来测量调用算法的持续时间。
- 我们在一个循环中进行多次测量,以使持续时间更加成熟。 结果在很大程度上取决于所使用的硬件、C++编译器和C++库。在我的笔记本电脑上(在英特尔i7上使用Visual C++,带有2个核心和超线程),我们得到的结果如下。
- 在100个元素的情况下,顺序算法要快10倍以上。这是因为启动和管理线程需要太多的时间,对于几个元素来说不值得。
- 对于10,000个元素,我们接近于收支平衡。
- 对于1,000,000个元素,并行执行的速度大约是3倍。
同样,这也不是一个一般性的证明,在什么地方和什么时候并行算法是值得的。但它表明,即使对于非微不足道的数字运算,也值得使用它们。关键是,它值得用在
- 长操作
- 许多许多元素 例如,使用并行版本的算法count_if()计算一个ints vector中的偶数元素的数量是不值得的。元素的并行版本是不值得的;即使有1,000,000,000个元素也不值得。
auto num = std::count_if(std::execution::par, // execute policy
coll.cbegin(), coll.cend(), // 范围
[](int elem){ //准则
return elem % 2 == 0;
});
事实上,对于本例中具有快速谓词的简单算法,并行运行可能永远不会有回报。每个元素都应该发生一些需要大量时间的事情,并且与其他元素的处理无关。 但你无法预测任何事情,因为何时以及如何使用并行线程,都取决于C++标准库的实现者。事实上,无法控制使用多少线程,实现者可能会决定只在一定数量的元素上使用多线程。 测量! 用你的目标平台上的典型场景。
22.1.2 使用并行的sort()
排序是另一个例子,并行算法可以提供帮助。因为排序标准对每个元素的使用不只一次,你可以节省大量时间。 例如,考虑一下,我们初始化一个字符串的向量如下:
std::vector<std::string> coll;
for (int i=0; i < numElems / 2; ++i) {
coll.emplace_back("id" + std::to_string(i));
coll.emplace_back("ID" + std::to_string(i));
}
也就是说,我们创建一个以 “id “或 “ID “开头的元素向量,后面是一个整数:
id0 ID0 id1 ID1 id2 ID2 id3 ... id99 ID99 id100 ID100 ...
我们可以像往常一样按以下顺序对元素进行排序:
sort(coll.begin(), coll.end());
现在也可以通过明确传递一个 “顺序 “执行策略来实现:
sort(std::execution::seq, coll.begin(), coll.end());
如果在运行时决定是顺序运行还是并行运行,并且你不想有不同的函数调用,那么将顺序执行作为参数传递会很有用。 要求用并行排序来代替是很容易的:
sort(std::execution::par, coll.begin(), coll.end());
请注意,还有另一个并行执行策略:
sort(std::execution::par_seq, coll.begin(), coll.end());
我稍后将解释其中的区别。 所以,问题又来了,(什么时候)使用并行排序更好?在我的笔记本电脑上,只有10,000个字符串,你可以看到排序的时间是顺序排序的一半。而且,即使是对1000个字符串进行排序,使用并行执行也略胜一筹。
与其他改进措施相结合
请注意,还有其他的修改可能会给你带来更多或额外的好处。例如,如果我们只按数字排序,使用没有两个前导字符的子串,我们可以在谓词中使用字符串操作,并再次看到并行执行的2倍的改进:
sort(std::execution::par,
coll.begin(), coll.end(),
[] (const auto& a, const auto& b) {
return a.substr(2) < b.substr(2);
});
然而,substr()对于字符串来说是一个相当昂贵的成员函数,因为它创建并返回一个新的临时字符串。通过使用string_view类,我们甚至在连续执行的情况下,也会比以前好3倍。顺序执行的情况下,我们的速度也会提高3倍:
sort(coll.begin(), coll.end(),
[] (const auto& a, const auto& b) {
return std::string_view{a}.substr(2) < std::string_view{b}.substr(2);
});
结合使用并行算法,我们的速度提高了多达 10 倍:
sort(std::execution::par,
coll.begin(), coll.end(),
[] (const auto& a, const auto& b) {
return std::string_view{a}.substr(2) < std::string_view{b}.substr(2);
});
与使用字符串的 substr() 成员的顺序执行相比:
sort(coll.begin(), coll.end(),
[] (const auto& a, const auto& b) {
return a.substr(2) < b.substr(2);
22.2 执行策略
你可以把不同的执行策略作为第一个参数传递给并行STL算法。它们被定义在头文件中。表Execution Policies列出了标准化的执行策略。
| 策略 | 意义 |
|---|---|
| std::execution::seq | 顺序执行 |
| std::execution::par | 并行顺序执行 |
| std::execution::par_unseq | 并行无序列(矢量)执行 |
让我们详细讨论一下执行策略。
- 使用seq的顺序执行 意味着和非并行算法一样,当前的执行线程按顺序逐个元素执行必要的操作。使用这个策略的行为应该和使用非并行方式调用算法一样,根本不需要传递任何执行策略。然而,对于接受这个参数的并行算法,可能会有额外的限制,比如for_each()不返回任何值,或者所有的迭代器必须至少是前向迭代器。 提供这个策略是为了能够通过传递一个不同的参数而不是使用一个不同的签名来请求顺序执行。但是请注意,采用这种策略的并行算法的行为可能与相应的非并行算法略有不同。
- 使用par的并行顺序执行 意味着多个线程可能依次执行元素的必要操作。当一个算法开始执行必要的操作时,它在处理其他元素之前完成这一执行。 与par_unseq相比,这可以确保没有问题或死锁发生,因为在处理完一个元素的步骤后,需要在同一个线程对另一个元素执行第一步之前调用另一个步骤。
- 使用par_unseq的并行无序执行 意味着多个线程可能为多个元素执行必要的操作,但不能保证一个线程执行该元素的所有步骤而不切换到其他 元素。这特别是使矢量执行成为可能,在这种情况下,一个线程可能首先执行多个元素的第一步 在执行下一个步骤之前,一个线程可能首先执行多个元素的执行步骤。
并行的无序执行需要编译器/硬件的特别支持,以检测哪里和如何操作可以被矢量化。操作如何被矢量化。
22.3 异常处理
所有的并行算法都会调用std::terminate(),如果元素访问函数通过一个未捕获的异常退出。 请注意,如果选择的是顺序执行策略,这也适用。如果不能接受这种情况,使用算法的非并行版本可能是更好的选择。 还要注意的是,并行算法仍有可能被抛出。如果它们不能为并行执行获得临时的内存资源,它们会抛出std::bad_alloc。然而,没有其他 可能会被抛出。
22.4 不使用并行算法的好处
有了调用并行算法的能力,以及它们甚至提供了一个顺序执行策略的事实,可能会出现这样的问题:我们是否还需要非并行算法。 然而,除了向后兼容之外,使用非并行算法可能有很大的好处。
- 可以使用输入和输出迭代器。
- 算法不会在异常情况下terminate()。
- 算法可以避免由于非故意使用元素而产生的副作用。
- 算法可能提供额外的功能,例如for_each()返回传递的可调用,以便能够处理其结果状态。
22.5 并行算法的概述
表Unmodified Parallel STL Algorithms列出了标准化的算法,可以不加任何修改地支持并行处理。 表Modified Parallel STL Algorithms列出了经过一些修改的支持并行处理的标准化算法。 表STL算法无并行化列出了不支持并行处理的算法。 请注意,对于 accumulate() 和 inner_product() ,新的并行算法被提供了宽松的要求。放宽了要求。
| 算法 | 备注 |
|---|---|
| find_end(), adjacent_find() | 除了搜索者 |
| search(), search_n() | |
| swap_ranges() | |
| replace(), replace_if() | |
| fill() | |
| generate() | |
| remove(), remove_if() | |
| unique() | |
| reverse() | |
| rotate() | |
| partition(), stable_partition() | |
| sort(), stable_sort(), partial_sort() | |
| is_sorted(), is_sorted_until() | |
| nth_element() | |
| inplace_merge() | |
| is_heap(), is_heap_until() | |
| min_element(), max_element(), min_max_element() | 除了搜索者 |
| for_each() | 前向迭代器和返回类型 void |
| all_of(), any_of(), none_of() | 前向迭代器 |
| for_each_n() | |
| find(), find_if(), find_if_not() | |
| find_first_of() | |
| count(), count_if() | |
| mismatch() | |
| equal() | |
| is_partitioned() | |
| partial_sort_copy() | |
| includes() | |
| lexicographical_compare() | |
| fill_n() | |
| generate_n() | |
| reverse_copy() | |
| rotate_copy() | |
| copy(), copy_n(), copy_if() | |
| move() | |
| transform() | |
| replace_copy(), replace_copy_if() | |
| remove_copy(), remove_copy_if() | |
| unique_copy() | |
| partition_copy() | |
| merge() | |
| set_union(), set_intersection() | |
| set_difference(), set_symmetric_difference() | |
| exclusive_scan(), inclusive_scan() | 前向迭代器 |
| accumulate(), inner_product(), partial_sum() | 改用 reduce() 和 transform_reduce() |
| search() with searcher | |
| copy_backward() move_backward() | |
| sample(), shuffle() | |
| partition_point() | |
| lower_bound(), upper_bound(), equal_range() | |
| binary_search() | |
| is_permutation(), next_permutation(), prev_permutation() | |
| push_heap(), pop_heap(), make_heap(), sort_heap() | 改用 reduce() 和 transform_reduce() |
22.6 并行处理的新算法
一些补充算法被引入,以处理自C++98以来可用的标准算法的并行处理。
22.6.1 reduce()
例如,reduce()是作为 accumulate()的平行形式引入的,它 “累积 “所有元素(你可以定义,哪个操作执行 “累积”)。例如,考虑以下 accumulate() 的用法。
lib/accumulate.cpp
#include <iostream>
#include <vector>
#include <numeric> // for accumulate()
void printSum(long num)
{
// 用 1 2 3 4 的 num 个序列创建 coll:
std::vector<long> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {1, 2, 3, 4});
}
auto sum = std::accumulate(coll.begin(), coll.end(),
0L);
std::cout << "accumulate(): " << sum << '\n';
}
int main()
{
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
我们计算所有元素的总和,输出:
accumulate(): 10
accumulate(): 10000
accumulate(): 10000000
换算运算的平行化
这个程序可以通过改用reduce()来实现并行化:
lib/reduce.cpp
#include <iostream>
#include <vector>
#include <numeric> // for reduce()
#include <execution>
void printSum(long num)
{
// 用 1 2 3 4 的 num 个序列创建 coll:
std::vector<long> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {1, 2, 3, 4});
}
auto sum = std::reduce(std::execution::par,
coll.begin(), coll.end(),
0L);
std::cout << "reduce(): " << sum << '\n';
}
int main()
{
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
在输出相同的情况下,现在的程序可能运行得更快或更慢(取决于是否支持启动多线程,以及所花费的时间是否比我们并行运行算法所节省的时间多)。 这里使用的操作是+,它是换元的,所以加入积分元素的顺序并不重要。
非共轭运算的并行化
然而,对于浮点值来说,顺序很重要,这就证明了以下程序:
lib/reducefloat.cpp
#include <iostream>
#include <vector>
#include <numeric>
#include <execution>
void printSum(long num)
{
// 用 0.1 0.3 0.0001 的 num 个序列创建 coll:
std::vector<double> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {0.1, 0.3, 0.00001});
}
auto sum1 = std::accumulate(coll.begin(), coll.end(),
0.0);
std::cout << "accumulate(): " << sum1 << '\n';
auto sum2 = std::reduce(std::execution::par,
coll.begin(), coll.end(),
0.0);
std::cout << "reduce(): " << sum2 << '\n';
std::cout << (sum1==sum2 ? "equal\n" : "differ\n");
}
#include<iomanip>
int main()
{
std::cout << std::setprecision(20);
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
这里我们同时使用 accumulate() 和 reduce() 并比较结果。一个可能的输出是:
accumulate(): 0.40001
reduce(): 0.40001
equal
accumulate(): 400.01
reduce(): 400.01
differ
accumulate(): 400010
reduce(): 400010
differ
accumulate(): 4.0001e+06
reduce(): 4.0001e+06
differ
虽然结果看起来是一样的,但有时会有差异。这可能是以不同的顺序添加 的顺序不同而造成的。 如果我们改变打印浮点值的精度:
std::cout << std::setprecision(20);
我们可以看到结果值略有不同:
accumulate(): 0.40001000000000003221
reduce(): 0.40001000000000003221
equal
accumulate(): 400.01000000000533419
reduce(): 400.01000000000010459
differ
accumulate(): 400009.99999085225863
reduce(): 400009.9999999878346
differ
accumulate(): 4000100.0004483023658
reduce(): 4000100.0000019222498
differ
由于没有定义是否、何时以及如何实现并行算法,因此在某些平台上的结果可能看起来是一样的(达到一定数量的元素)。
非关联性操作的并行化
现在让我们改变一下操作,通过总是添加每个值的平方来累积值:
lib/accumulate2.cpp
#include <iostream>
#include <vector>
#include <numeric> // 对于 accumulate()
void printSum(long num)
{
// 用 1 2 3 4 的 num 个序列创建 coll:
std::vector<long> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {1, 2, 3, 4});
}
auto squaredSum = [] (auto sum, auto val) {
return sum + val * val;
};
auto sum = std::accumulate(coll.begin(), coll.end(),
0L,
squaredSum);
std::cout << "accumulate(): " << sum << '\n';
}
int main()
{
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
在这里,我们传递一个lambda,对于每一个值,都要取当前的和,并加上新值的平方:
auto squaredSum = [] (auto sum, auto val) {
return sum + val * val;
};
使用 accumulate() 输出看起来很好:
accumulate(): 30
accumulate(): 30000
accumulate(): 30000000
accumulate(): 300000000
但是,让我们使用 reduce() 切换到并行处理:
lib/reduce2.cpp
#include <iostream>
#include <vector>
#include <numeric> // 对于reduce()
#include <execution>
void printSum(long num)
{
// 用 1 2 3 4 的 num 个序列创建 coll:
std::vector<long> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {1, 2, 3, 4});
}
auto squaredSum = [] (auto sum, auto val) {
return sum + val * val;
};
auto sum = std::reduce(std::execution::par,
coll.begin(), coll.end(),
0L,
squaredSum);
std::cout << "reduce(): " << sum << '\n';
}
int main()
{
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
输出可能会变成这样:
reduce(): 30
reduce(): 30000
reduce(): -425251612
reduce(): 705991074
是的,结果有时可能是错误的。问题是,该操作不是关联性的。例如,如果我们对元素1、2和3应用这个操作,我们可能先计算0+11和2+33,但当我们把中间的结果结合起来时,我们又把3平方了,基本上是 计算:
(0+1*1) + (2+3*3) * (2+3*3)
但为什么这里的结果有时是正确的呢?嗯,似乎在这个平台上,reduce()只在一定数量的元素中并行运行。而这是完全可以的。因此,使用有足够多元素的测试案例来检测这样的问题。 解决这个问题的方法是使用另一种新的算法,transform_reduce()。它把我们要对每个元素进行的修改(这是我们可以并行化的一件事)和结果的累积分开,只要它是换元的(这是我们可以并行化的另一件事)。
lib/transformreduce.cpp
#include <iostream>
#include <vector>
#include <numeric> // for transform_reduce()
#include <execution>
#include <functional>
void printSum(long num)
{
// 用 1 2 3 4 的 num 个序列创建 coll:
std::vector<long> coll;
coll.reserve(num * 4);
for (long i=0; i < num; ++i) {
coll.insert(coll.end(), {1, 2, 3, 4});
}
auto sum = std::transform_reduce(std::execution::par,
coll.begin(), coll.end(),
0L,
std::plus{},
[] (auto val) {
return val * val;
});
std::cout << "transform_reduce(): " << sum << '\n';
}
int main()
{
printSum(1);
printSum(1000);
printSum(1000000);
printSum(10000000);
}
在调用transform_reduce()时,我们传递了
- 执行策略,以便(允许)并行地运行这个程序
- 要处理的值的范围
- 0L作为外部累加的初始值
- 操作+作为外部累加的操作
- 一个lambda,用于在累加之前处理每个值
transform_reduce()可能是迄今为止最重要的并行算法,因为我们经常在合并数值之前修改它们(也称为map reduce原则)。
用于文件系统操作的transform_reduce()函数
下面是另一个并行运行transform_reduce()的例子:
lib/dirsize.cpp
#include <vector>
#include <iostream>
#include <numeric> // for transform_reduce()
#include <execution> // 对于执行策略
#include <filesystem> // filesystem library
int main(int argc, char* argv[])
{
// 根目录作为命令行参数被传递:
if (argc < 2) {
std::cout << "Usage: " << argv[0] << " <path> \n";
return EXIT_FAILURE;
}
std::filesystem::path root{argv[1]};
// 在通过的文件树中启动所有文件路径的列表:
std::vector<std::filesystem::path> paths;
try {
std::filesystem::recursive_directory_iterator dirpos{root};
std::copy(begin(dirpos), end(dirpos),
std::back_inserter(paths));
}
catch (const std::exception& e) {
std::cerr << "EXCEPTION: " << e.what() << std::endl;
return EXIT_FAILURE;
}
// 累积所有常规文件的大小:
auto sz = std::transform_reduce(
std::execution::par, // 并行执行
paths.cbegin(), paths.cend(), // range
std::uintmax_t{0}, // 初始值
std::plus<>(), // accumulate ...
[](const std::filesystem::path& p) { // 如果是普通文件,文件大小
return is_regular_file(p) ? file_size(p)
: std::uintmax_t{0};
});
std::cout << "size of all " << paths.size()
<< " regular files: " << sz << '\n';
}
首先,我们递归地收集作为命令行参数的目录中的所有文件系统路径:
std::filesystem::path root{argv[1]};
std::vector<std::filesystem::path> paths;
std::filesystem::recursive_directory_iterator dirpos{root};
std::copy(begin(dirpos), end(dirpos),
std::back_inserter(paths));
请注意,由于我们可能会传递一个无效的路径,可能的(文件系统)异常会被捕获。 然后,我们遍历文件系统路径的集合,积累它们的大小,如果它们是 正常的文件:
auto sz = std::transform_reduce(
std::execution::par, // 并行执行
paths.cbegin(), paths.cend(), // range
std::uintmax_t{0}, // initial value
std::plus<>(), // accumulate ...
[](const std::filesystem::path& p) { // 文件大小(如果是常规文件)
return is_regular_file(p) ? file_size(p)
: std::uintmax_t{0};
});
新的标准算法transform_reduce()的操作方法如下。
- 最后一个参数被应用于每个元素。在这里,对每个路径元素调用传递的lambda,如果它是一个普通文件,则查询其大小。
- 第二个但也是最后一个参数是合并所有大小的操作。因为我们要累积大小,所以我们使用标准函数对象std::plus<>。
- 第三个但也是最后一个参数是合并所有大小的操作的初始值。因此,如果路径列表是空的,我们从0开始。我们使用与file_size()的返回值相同的类型,std::uintmax_t。
请注意,询问文件的大小是一个相当昂贵的操作,因为它需要一个操作系统调用。由于这个原因,使用一个算法来调用这个转换(从路径到大小),并以任何顺序与多个线程并行,并计算出总和,是非常快的回报。第一次测量显示了一个明显的胜利(程序的速度提高了一倍)。 还要注意的是,你不能把目录迭代器所迭代的路径直接传递给并行的 算法,因为目录迭代器是输入迭代器,而并行算法需要正向的 迭代器。 最后请注意,transform_reduce()被定义在头文件中,而不是。 (就像 accumulate() 一样,它也算作数字算法。
22.7 并行算法的详细介绍
22.8 后记
2012 年,Jared Hoberock Michael Garland Olivier Giroux Vinod Grover、Ujval Kapasi 和 Jaydeep Marathe 在 https://wg21.link/n3408 中首次提出了并行化 STL 算法。 它成为了一个正式的 beta 标准,即并行 C++ 扩展技术规范(参见 https://wg21.link/n3850)。 Jared Hoberock、Grant Mercer、Agustin Berge 和 Harmut Kaiser 在 https://wg21.link/n4276 中添加了其他算法。 通过 https://wg21.link/p0024r2,Jared Hoberock 提出的标准库采用了 C++ 并行扩展技术规范。 JF Bastien 和 Bryce Adelstein Lelbach 在 https://wg21.link/p0394r4 中提出的异常处理被接受。
23 子字符串和子序列搜索
自C++98以来,C++标准库提供了一种搜索算法来寻找一个范围内元素的子序列。然而,存在着不同的搜索算法。例如,通过预先计算关于要搜索的模式的统计数据,这些算法对于特殊的任务,如在一个大文本中寻找子串,可以有明显的表现。 因此,C++17引入了Boyer-Moore和Boyer-Moore-Horspool搜索算法以及使用它们的各种接口。它们特别适用于搜索大文本中的子串,但也可以改进寻找容器或范围中的子序列。
23.1 使用子串搜索器
新的搜索器是专门为搜索大型文本中的字符串(例如,单词或短语)而开发的。 因此,让我们首先演示一下在这种情况下如何使用它们,以及你如何利用它们来获益。
23.1.1 通过search()使用搜索器
我们现在有以下选项来搜索一个字符串文本中的子串子:
- 字符串成员 find():
std::size_type idx = text.find(sub)。
- 算法搜索()。
auto pos = std::search(text.begin(), text.end(),
sub.begin(), sub.end())。
- 并行算法 search():
auto pos = std::search(std::execution::par,
text.begin(), text.end(), sub.begin(), sub.end())。
- 使用 default_searcher:
auto pos = std::search(text.begin(), text.end(),
std::default_searcher{sub.begin(), sub.end()})。
- 使用boyer_moore_searcher:
auto pos = std::search(text.begin(), text.end(),
std::boyer_moore_searcher{sub.begin(), sub.end()})。
- 使用boyer_moore_horspool_searcher:
auto pos = std::search(text.begin(), text.end(),
std::boyer_moore_horspool_searcher{sub.begin(),
sub.end()})。
新的搜索器被定义在中。 Boyer-Moore和Boyer-Moore-Horspool搜索器是众所周知的算法,在搜索开始前预先计算表格(哈希值),以提高搜索的速度,如果搜索覆盖了相当大的文本和/或子串。使用它们,算法需要随机访问的迭代器(而不是正向迭代器,这对于天真的搜索()来说已经足够了)。
在lib/searcher1.cpp中,你可以找到一个完整的程序,演示如何使用这些不同的方式来搜索子串。 请注意,所有search()的应用都会产生一个指向匹配子串的第一个字符的迭代器。如果没有,则返回文本的末端。这样我们就可以搜索到一个子串的所有出现,如下所示。
std::boyer_moore_searcher bm{sub.begin(), sub.end()};
for (auto pos = std::search(text.begin(), text.end(), bm);
pos != text.end();
pos = std::search(pos+sub.size(), text.end(), bm)) {
std::cout << "Found '" << sub << "' at index " << pos - text.begin() << '\n';
}
搜索器的性能
哪一种是搜索子字符串的最佳方法(最快和/或最少的内存)? 这个问题的一个特殊方面是我们现在也可以在并行模式下使用传统的 search() (使用新的搜索器时这是不可能的)。 答案取决于具体情况:
-
仅使用(非并行)search() 通常是最慢的,因为对于文本中的每个字符,我们开始找出子字符串是否匹配。
-
使用 default_searcher 应该是等价的,但我看到更糟糕的运行时间高达 3 倍。
-
使用find()可能会更快,但这取决于库中实现的质量。在我所做的测量中,我看到与search()相比,运行时间提高了20%到100倍之间。
-
对于文本和相当大小的子串,boyer_moore_searcher应该是最快的。与search()相比,我看到了50倍甚至100倍的改进。在有大量子串的大文本中,这始终是最快的搜索。
-
boyer_moore__horspool_searcher以空间换时间。它通常比boyer_moore_searcher慢,但不应该使用那么多内存。我看到的改进在不同的平台上确实有很大的不同。在一个平台上,它接近boyer_moore(比search()好50倍,比find()好10倍),而在其他平台上,对search()的改进只有2或3倍,而使用find()则快得多。
-
使用并行的search()与普通的search()相比,我得到了3倍的支持,看起来使用Boyer-Moore搜索器通常还是要快很多。
所以我只能给出一个建议。测量! 在你的目标平台上测试典型场景。
这是值得的,因为你可能会得到100倍的改进(例如,我在一个有1000万个字符的字符串中搜索一个接近结尾的1000个字符的子串)。
lib/searcher1.cpp中的代码还打印了不同搜索选项的测量值,这样你就可以比较你的平台上的数字。
23.1.2 直接使用搜索器
或者,你可以使用搜索器的函数调用操作,它返回一对开始和结束的一对子序列。 代码看起来如下。
std::boyer_moore_searcher bm{sub.begin(), sub.end()};
...;
for (auto begend = bm(text.begin(), text.end());
begend.first != text.end();
begend = bm(begend.second, text.end())) {
std::cout << "found '" << sub << "' at index "
<< begend.first - text.begin() << '-'
<< begend.second - text.begin() << '\n';
}
然而,由于你可以使用std::tie()将新的值重新分配给结构化绑定的 std::pair<>,你可以将代码简化如下:
std::boyer_moore_searcher bm{sub.begin(), sub.end()};
...;
for (auto [beg, end] = bm(text.begin(), text.end());
beg != text.end();
std::tie(beg,end) = bm(end, text.end())) {
std::cout << "found '" << sub << "' at index "
<< beg - text.begin() << '-'
<< end - text.begin() << '\n';
}
只是直接使用搜索器寻找子串的第一次出现,你可以使用如果与 初始化和结构化绑定:
std::boyer_moore_searcher bm{sub.begin(), sub.end()};
...;
if (auto [beg, end] = bm(text.begin(), text.end()); beg != text.end()) {
std::cout << "found '" << sub << "' first at index "
<< beg - text.begin() << '-'
<< end - text.begin() << '\n';
}
23.2 使用通用子序列搜索器
Boyer-Moore 和 Boyer-Moore-Horspool 是作为字符串搜索器开发的。 但是,C++17 采用它们作为通用算法,以便您可以使用它们在容器或范围中查找元素的子序列。 也就是说,您现在可以实现以下内容:
std::vector<int> coll;
...;
std::deque<int> sub{0, 8, 15, ...};
pos = std::search(coll.begin(), coll.end(),
std::boyer_moore_searcher{sub.begin(), sub.end()});
同样,您还可以使用搜索器的函数调用运算符:
std::vector<int> coll;
...;
std::deque<int> sub{0, 8, 15, ...};
std::boyer_moore_searcher bm{sub.begin(), sub.end()};
auto [beg, end] = bm(coll.begin(), coll.end());
if (beg != coll.end) {
std::cout << "found subsequence at << " beg - coll.begin() << '\n';
}
为了实现这一点,元素必须能够在哈希表中使用(即必须提供一个默认的哈希函数,并且必须支持用==来比较两个元素)。如果不是这种情况,你可以使用谓词(如下所述)。
再说一遍。测量发现你在性能(速度和内存)方面的好处。在尝试一些例子时,我看到了更多不同的因素。例如,使用boyer_moore_searcher可以将搜索的速度再次提高100倍(这又比使用并行算法快多了)。但是使用boyer_moore_horspool_searcher可以使搜索速度提高50倍,但也会慢2倍。
lib/searcher2.cpp中的代码演示了对一个向量中的子序列的不同搜索,还打印了不同搜索选项的测量结果,这样你就可以比较 在你的平台上进行比较。
23.3 使用搜索器的谓词
使用搜索时,您可以使用谓词,这可能是必要的,原因有两个:
-
您想定义自己的方式来比较两个元素。
-
你想提供一个哈希函数,这对于 Boyer-Moore(-Horspool) 搜索器是必需的。 您必须将谓词作为附加参数提供给搜索器的构造函数。 例如,这里我们不区分大小写地搜索子字符串:
std::boyer_moore_searcher bmic{substr.begin(), substr.end(),
[](char c){
return std::hash<char>{}(std::toupper(c));
},
[](char c1, char c2){
return std::toupper(c1)==std::toupper(c2);
}
};
auto begend = bmic(sub.begin(), sub.end());
在散列值之前不要忘记调用 toupper(),否则你违反了散列值对于所有值必须相同的要求,其中 operator== 产生 true。 在这里,如果我们有一个类 Customer 定义如下:
class Customer {
...;
public:
Customer() = default;
std::string getID() const {
return id;
}
friend bool operator== (const Customer& c1, const Customer& c2) {
return c1.id == c2.id;
}
};
我们可以在Customer vector中搜索客户子序列,如下所示:
std::vector<Customer> customers;
...;
std::vector<Customer> sub{...};
...;
std::boyer_moore_searcher bmcust(sub.begin(), sub.end(),
[](const Customer& c) {
return std::hash<std::string>{}(c.getID());
});
auto pos = bmcust(customers.begin(), customers.end());
if (pos.first != customers.end()) {
...;
}
但是请注意,使用谓词可能会给使用搜索器带来很大的开销,所以只有当你有大量的元素并搜索一个相当大的子序列时才值得使用它们(例如,在100万个客户的集合中寻找1000个客户的子序列)。 再次强调。要有大的思维,要有大的度量。
23.4 后记
这些搜索最初是由 Marshall Clow 在 https://wg21.link/n3411 中提出的,将 Boost.Algorithm 作为参考实现。 它们成为第一个图书馆基础 TS 的一部分。 对于 C++17,它们随后与 Beman Dawes 和 Alisdair Meredith 在 https://wg21.link/p0220r1 中提出的其他组件一起采用,包括 Marshall Clow 在 https://wg21.link/p0253R1 中提出的接口修复。
24 其他工具函数和算法
C++17 提供了一些新的实用函数和算法,本章将对其进行介绍。
24.1 size(), empty(), and data()
为了支持通用代码的灵活性,C++标准库提供了三个新的辅助函数:size()、empty()和data()。 正如其他用于泛型代码迭代范围和集合的全局辅助函数std::begin(), std::end(), 和std::advance()一样,这些函数被定义在头文件中。
24.1.1 通用的size()函数
通用的std::size()函数允许我们询问任何范围的大小,只要它有一个迭代器接口或者是一个原始数组。有了它,你可以写这样的代码:
lib/last5.hpp
#ifndef LAST5_HPP
#define LAST5_HPP
#include <iterator>
#include <iostream>
template<typename T>
void printLast5(const T& coll)
{
// 计算大小:
auto size{std::size(coll)};
// 前进到从最后 5 个元素开始的位置
std::cout << size << " elems: ";
auto pos{std::begin(coll)};
if (size > 5) {
std::advance(pos, size - 5);
std::cout << "... ";
}
// 打印剩余元素:
for ( ; pos != std::end(coll); ++pos) {
std::cout << *pos << ' ';
}
std::cout << '\n';
}
#endif // LAST5_HPP
在这里,与
auto size{std::size(coll)};
我们用传递的集合的大小来初始化 size,它要么映射到 coll.size() 要么映射到传递的原始数组的大小。 因此,如果我们调用:
std::array arr{27, 3, 5, 8, 7, 12, 22, 0, 55};
std::vector v{0.0, 8.8, 15.15};
std::initializer_list<std::string> il{"just", "five", "small", "string",
"literals"};
printLast5(arr);
printLast5(v);
printLast5(il);
输出是:
9 elems: ... 7 12 22 0 55
3 elems: 0 8.8 15.15
5 elems: just five small string literal
并且因为支持原始 C 数组,我们也可以调用:
printLast5("hello world");
打印:
12 elems: ... o r l d
请注意,此函数模板因此替换了使用 countof 或 ARRAYSIZE 定义为类似以下内容的计算数组大小的常用方法:
#define ARRAYSIZE(a) (sizeof(a)/sizeof(*(a)))
另请注意,您不能将内联定义的初始化列表传递给 last5<>()。 原因是模板参数不能推导出 std::initializer_list()。 为此,您必须使用以下声明重载 last5():
template<typename T>
void printLast5(const std::initializer_list<T>& coll)
最后,请注意此代码不适用于 forward_list<>,因为转发列表没有成员函数 size()。 所以,如果你只想检查集合是否为空,你最好使用std::empty(),这将在后面讨论。
24.1.2 通用的empty()函数
与新的全局 size() 类似,新的通用 std::empty() 允许我们检查容器、原始 C 数组或 std::initializer_list<> 是否为空。 因此,与上面的示例类似,您可以一般地检查传递的集合是否为空:
if (std::empty(coll)) {
return;
}
与 std::size() 相比,std::empty() 也适用于前向列表/
24.1.3 通用的data()函数
最后,新的通用 std::data() 函数允许我们访问具有 data() 成员和原始数组的容器的原始数据。 容器、原始 C 数组或 std::initializer_list<>。 例如,以下代码每隔一个元素打印一次:
lib/data.hpp
#ifndef DATA_HPP
#define DATA_HPP
#include <iterator>
#include <iostream>
template<typename T>
void printData(const T& coll)
{
// 每隔一个元素打印一次:
for (std::size_t idx{0}; idx < std::size(coll); ++idx) {
if (idx % 2 == 0) {
std::cout << std::data(coll)[idx] << ' ';
}
}
std::cout << '\n';
}
#endif // DATA_HPP
因此,如果我们调用:
std::array arr{27, 3, 5, 8, 7, 12, 22, 0, 55};
std::vector v{0.0, 8.8, 15.15};
std::initializer_list<std::string> il{"just", "five", "small", "string",
"literals"};
printData(arr);
printData(v);
printData(il);
printData("hello world");
输出:
27 5 7 22 55
0 15.15
just small literals
h l o w r d
24.2 as_const()
新的辅助函数 std::as_const() 将值转换为相应的 const 值,而不使用 static_cast<> 或 add_const_t<> 类型特征。 它允许我们强制为非 const 对象调用函数的 const 重载,以防万一:
std::vector<std::string> coll;
foo(coll); // 喜欢非常量重载
foo(std::as_const(coll)); // 强制使用 const 重载
如果 foo() 是一个函数模板,这也将强制将模板实例化为 const 类型而不是原始的非常量类型。
24.2.1 通过常量引用进行捕获
as_const() 的一种应用是通过 const 引用捕获 lambda 参数的能力。 例如:
std::vector<int> coll {8, 15, 7, 42};
auto printColl = [&coll = std::as_const(coll)] {
std::cout << "coll: ";
for (int elem : coll) {
std::cout << elem << ' ';
}
std::cout << '\n';
};
现在调用:
printColl();
将打印 coll 的当前状态,而不会有意外修改其值的危险。
24.3 clamp()
C++17 提供了一个新的实用函数clamp(),它可以在传递的最小值和最大值之间“钳制”一个值。 它是 min() 和 max() 的组合调用。 例如:
lib/clamp.cpp
#include <iostream>
#include <algorithm> // for sample()
int main()
{
for (int i : {-7, 0, 8, 15}) {
std::cout << std::clamp(i, 5, 13) << '\n';
}
}
调用clamp(i, 5, 13) 与调用std::min(std::max(i, 5), 13) 的效果相同,因此程序具有以下输出:
5
5
8
13
至于 min() 和 max(),clamp() 要求所有通过 const 引用传递的参数都具有相同的类型 T:
namespace std {
template<typename T>
constexpr const T& clamp(const T& value, const T& min, const T& max);
}
返回值是对传递参数之一的 const 引用。 如果传递不同类型的参数,则可以显式指定模板参数 T:
double d{4.3};
int max{13};
...
std::clamp(d, 0, max); // 编译时错误
std::clamp<double>(d, 0, max); // OK
你也可以传递浮点值,只要它们没有 NaN 值。 至于 min() 和 max() 你可以传递一个谓词作为比较操作。 例如:
for (int i : {-7, 0, 8, 15}) {
std::cout << std::clamp(i, 5, 13,
[] (auto a, auto b) {
return std::abs(a) < std::abs(b);
})
<< '\n';
}
具有以下输出:
-7
5
8
13
因为 -7 的绝对值介于 5 和 13 的绝对值之间,所以在这种情况下,clamp() 产生 -7。 没有采用值的初始化列表(如 min() 和 max() 所具有的)的 clamp() 的重载。
24.4 sample()
通过sample(),C++17提供了一种算法,可以从一个给定的数值范围(群体)中提取一个随机子集(样本)。这有时被称为蓄水池采样或选择采样。 考虑一下下面的例子程序。
lib/sample1.cpp
#include <iostream>
#include <vector>
#include <string>
#include <iterator>
#include <algorithm> // for clamp()
#include <random> // for default_random_engine
int main()
{
// 初始化一个包含 10,000 个字符串值的vector:
std::vector<std::string> coll;
for (int i=0; i < 10000; ++i) {
coll.push_back("value" + std::to_string(i));
}
// 打印此集合的 10 个随机选择的值:
sample(coll.begin(), coll.end(),
std::ostream_iterator<std::string>{std::cout, "\n"},
10,
std::default_random_engine{});
}
在使用大量字符串值(value0、value1、…)初始化向量后,我们使用 sample() 来提取这些字符串值的随机子集:
// 打印此集合的 10 个随机选择的值:
sample(coll.begin(), coll.end(),
std::ostream_iterator<std::string>{std::cout, "\n"},
10,
std::default_random_engine{});
我们通过:
- 我们从中提取值子集的范围的开始和结束,
- 一个迭代器,用于将提取的值写入(这里是一个 ostream 迭代器将它们写入标准输出)
- 要提取的值的最大数量(我们可能会提取较少的值,范围太小)
- 用于计算随机子集的随机引擎
结果,我们打印了 coll 的 10 个元素的随机子集。 输出可能是:
value0
value488
value963
value1994
value2540
value2709
value2835
value3518
value5172
value7996
如您所见,元素的顺序是稳定的(与它们在 coll 中的顺序相匹配)。 但是,只有在传递范围的迭代器至少是前向迭代器时,才能保证这一点。 算法声明如下:
namespace std {
template<typename InputIterator, typename OutputIterator,
typename Distance, typename UniformRandomBitGenerator>
OutputIterator sample(InputIterator sourceBeg, InputIterator sourceEnd,
OutputIterator destBeg,
Distance num,
UniformRandomBitGenerator&& eng);
}
它具有以下规范和约束:
- 源范围的迭代器必须至少是输入迭代器,目标范围的迭代器必须至少是输出迭代器。 但是,两者都不可能。 如果源迭代器不是最小前向迭代器,则目标迭代器必须是随机访问迭代器。
- 像往常一样,目标迭代器会覆盖,如果没有足够的元素可以覆盖并且没有使用插入器,则会导致未定义的行为。
- 该算法返回最后一个复制元素之后的位置。
- 目标迭代器不得在传递的源范围内。
- num 可以是整数类型。 如果源范围内的元素不足,则提取源范围内的所有元素。
- 提取元素的顺序是稳定的,除非源范围内的迭代器是纯输入迭代器。
这是另一个演示 sample() 用法的示例:
lib/sample2.cpp
#include <iostream>
#include <vector>
#include <iterator>
#include <algorithm> // for clamp()
#include <random> // for default_random_engine
int main()
{
// initialize a vector of 10,000 string values:
std::vector<std::string> coll;
for (int i=0; i < 10000; ++i) {
coll.push_back("value" + std::to_string(i));
}
// 使用随机种子初始化 Mersenne Twister 引擎:
std::random_device rd; // 随机种子(如果支持)
std::mt19937 eng{rd()}; // Mersenne twister engine
// 初始化目标范围(必须足够大以容纳 10 个元素):
std::vector<std::string> subset;
subset.resize(100);
// 将 10 个随机选择的值从源范围复制到目标范围:
auto end = sample(coll.begin(), coll.end(),
subset.begin(),
10,
eng);
// 打印提取的元素(使用返回值作为新的结束):
for_each(subset.begin(), end,
[] (const auto& s) {
std::cout << "random elem: " << s << '\n';
});
}
在再次用大量字符串值(value0,value1,…)初始化一个vector之后,我们初始化一个用随机种子初始化的随机数引擎:
// 用一个随机种子初始化一个Mersenne Twister引擎:
std::random_device rd; // 随机种子(如果支持)
std::mt19937 eng{rd()}; // Mersenne Twister引擎
和一个目标范围:
// 初始化目标范围(必须足够大以容纳 10 个元素):
std::vector<std::string> subset;
subset.resize(100);
sample() 的调用现在将源范围的 10 个元素复制到目标范围:
// 将 10 个随机选择的值从源范围复制到目标范围:
auto end = sample(coll.begin(), coll.end(),
subset.begin(),
10,
eng);
返回值 end 初始化为包含最后一个随机提取的元素后面的位置,之后可以使用该位置,例如,打印提取的元素:
// 打印提取的元素(使用返回值作为新的结束):
for_each(subset.begin(), end,
[] (const auto& s) {
std::cout << "random elem: " << s << '\n';
});
24.5 for_each_n()
作为并行 STL 算法的一部分,提出了一种新算法 for_each_n(),该算法从 C++17 开始也以传统的非并行形式提供。 与 copy_n()、fill_n() 和 generate_n() 类似,它需要一个整数参数来将传递的可调用对象应用于给定范围的 n 个元素。
例如:
lib/foreachn.cpp
#include <iostream>
#include <vector>
#include <string>
#include <algorithm> // for for_each_n()
int main()
{
// 初始化一个包含 10,000 个字符串值的vector:
std::vector<std::string> coll;
for (int i=0; i < 10000; ++i) {
coll.push_back(std::to_string(i));
}
// 修改前 5 个元素:
for_each_n(coll.begin(), 5,
[] (auto& elem) {
elem = "value" + elem;
});
// 打印前 10 个元素:
for_each_n(coll.begin(), 10,
[] (const auto& elem) {
std::cout << elem << '\n';
});
}
在用大量字符串值(value0、value1、…)初始化一个vector后,我们首先修改前 5 个字符串:
for_each_n(coll.begin(), 5,
[] (auto& elem) {
elem = "value" + elem;
});
然后打印前 10 个字符串:
for_each_n(coll.begin(), 10,
[] (const auto& elem) {
std::cout << elem << '\n';
});
因此,该程序具有以下输出:
value0
value1
value2
value3
value4
5
6
7
8
9
算法声明如下:
namespace std {
template<typename InputIterator, typename Size, typename Function>
InputIterator for_each_n(InputIterator first, Size n, Function f);
}
请注意以下事项:
- for_each_n() 的非并行版本保证为每个元素按顺序调用传递的可调用对象。
- for_each_n() 算法作为迭代器返回最后处理的元素后面的位置。
- 由调用者确保给定范围有足够的元素。
- 传递的可调用对象的任何返回值都将被忽略。
该算法也可用作并行 STL 算法,它允许我们将任何函数应用于前 n 个元素,而无需保证任何顺序。
24.6 后记
size()、empty() 和 data() 最早由 Riccardo Marcangelo 在 https://wg21.link/n4017 中提出。 最终接受的措辞由 Riccardo Marcangelo 在 https://wg21.link/n4280 中制定。 as_const() 由 ADAM David Alan Martin 和 Alisdair Meredith 在 https://wg21.link/n4380 中首次提出。 最终接受的措辞由 ADAM David Alan Martin 和 Alisdair Meredith 在 https://wg21.link/p0007r1 中制定。 clamp() 由 Martin Moene 和 Niels Dekker 在 https://wg21.link/n4536 中首次提出。 最终接受的措辞由 Martin Moene 和 Niels Dekker 在 https://wg21.link/p002501 中制定。
sample() 由 Walter E. Brown 在 https://wg21.link/n3842 中首次提出。 最终接受的措辞由 Walter E. Brown 在 https://wg21.link/n3925 中制定。
25 容器扩展
C++ 标准库的标准容器有一些细微的变化,本章将对此进行描述。
25.1 支持不完整的容器类型
由于 C++17 需要 std::vector、std::list 和 std__forward_list 来支持不完整类型。 这样做的主要动机在 Matt Austern 的一篇名为“标准图书馆员:不完整类型的容器”的文章中进行了描述(参见 http://drdobbs.com/184403814):您现在可以拥有一个类型,它递归地拥有一个成员 其类型的容器。 例如:
struct Node
{
std::string value;
std::vector<Node> children; // 好的,因为 C++17(节点在这里是不完整的类型)
};
这也适用于具有私有成员和公共 API 的类。 这是一个完整的例子:
lib/incomplete.hpp
#ifndef NODE_HPP
#define NODE_HPP
#include <vector>
#include <iostream>
#include <string>
class Node
{
private:
std::string value;
std::vector<Node> children; // 好的,因为 C++17(节点在这里是不完整的类型)
public:
// 创建一个带值的节点:
Node(std::string s) : value{std::move(s)}, children{} {
}
// 添加子节点:
void add(Node n) {
children.push_back(std::move(n));
}
// 访问子节点:
Node& operator[](std::size_t idx) {
return children.at(idx);
}
// 递归打印节点树:
void print(int indent = 0) const {
std::cout << std::string(indent, ' ') << value << '\n';
for (const auto& n : children) {
n.print(indent+2);
}
}
...;
};
#endif // NODE_HPP
您可以使用此类,例如,如下所示:
lib/incomplete.cpp
#include "incomplete.hpp"
#include <iostream>
int main()
{
// 创建节点树:
Node root{"top"};
root.add(Node{"elem1"});
root.add(Node{"elem2"});
root[0].add(Node{"elem1.1"});
// print node tree:
root.print();
}
该程序具有以下输出:
top
elem1
elem1.1
elem2
25.2 节点处理程序
通过引入从关联或无序容器中拼接节点的能力,你可以轻松地:
- 修改键或(无序)maps或maps或(无序)集合。
- 在(无序) sets 和 maps中使用移动语义,以及
- 在(无序)sets 和 maps之间移动元素。
例如,在定义和初始化一个map后,如下所示。
std::map<int, std::string> m{{1,"mango"},
{2,"papaya"},
{3,"guava"}};
您可以使用键 2 修改元素,如下所示:
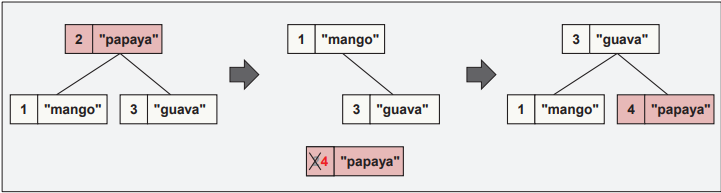
auto nh = m.extract(2); // nh 的类型为 decltype(m)::node_type
nh.key() = 4;
m.insert(std::move(nh));
代码将键为 2 的元素的节点从容器中取出,修改键,然后将其移回,如图 25.1 中所述。 请注意,不使用内存(取消)分配,并且对元素的指针和引用保持有效。 但是,在元素保存在节点句柄中时使用指针和引用会导致未定义的行为。
节点句柄的类型是 container::node_type。 它为会员提供
- 所有(无序)集合类型的value()
- 所有(无序)map类型的成员 key() 和 mapped()
您还可以使用节点句柄将元素从一个容器移动到另一个容器。 容器甚至可以通过以下方式有所不同:
- 一个支持重复,而另一个不支持(例如,您可以将元素从多地图移动到地图)
- 比较函数和散列函数可能不同
例子:
std::multimap<double, std::string> src {{1.1,"one"},
{2.2,"two"},
{3.3,"three"}};
std::map<double, std::string> dst {{3.3,"old data"}};
// 将一些元素从 multimap src 移动到 map dst:
dst.insert(src.extract(src.find(1.1))); // 使用迭代器拼接
dst.insert(src.extract(2.2)); // 使用键拼接
请注意, insert() 函数返回一个包含三个元素的结构(按以下顺序):
- 如果无法插入,则为现有元素的迭代器位置。
- 插入一个布尔值,表示插入是否成功。
- 如果无法插入,则带有节点句柄的 mode_type 节点。
即,关键信息是插入的第二个成员。 使用结构化绑定,您可以按如下方式使用返回值:
auto [pos,done,node] = dst.insert(src.extract(3.3));
if (!done) {
std::cout << "insert() of node handle failed:"
<< " tried to insert key '" << node.key()
<< "' with value '" << node.mapped()
<< "' but key exists with value '" << pos->second << "'\n";
}
25.3 后记
容器对不完整类型的支持首先是由 Matt Austern 在 http://drdobbs.com/184403814 中讨论的,最初是由袁志豪在 https://wg21.link/n3890 中提出的。 最终接受的措辞由袁志豪在 https://wg21.link/n4510 中制定。
节点句柄首先由 Alan Talbot 间接提出,请求拼接操作作为库问题 https://wg21.link/lwg839 和 Alisdair Meredith 请求对节点元素的移动支持作为库问题 https://wg21.link/lwg1041。 最终接受的措辞由 Alan Talbot、Jonathan Wakely、Howard Hinnant 和 James Dennett 在 https://wg21.link/p0083r3 中制定。 最终,Howard E. Hinnant 在 https://wg21.link/p0508r0 中稍微澄清了 API。
26 多线程和并发
在多线程和并发领域引入了一些小的扩展和改进。
26.1 补充的互斥和锁
26.1.1 std::scoped_lock
C++11 引入了一个简单的 std::lock_guard 来以一种简单的 RAII 风格的方式来锁定互斥锁:
- 构造函数锁
- 析构函数解锁(可能由异常引起)
不幸的是,这没有标准化为可变参数模板,以便能够通过单个声明锁定多个互斥锁。 std::scoped_lock<> 弥补了这一差距。 它允许我们锁定一个或多个互斥锁。 互斥锁可能有不同的互斥锁类型。 例如:
#include <mutex>
...;
std::vector<std::string> allIssues;
std::mutex allIssuesMx;
std::vector<std::string> openIssues;
std::timed_mutex openIssuesMx;
// lock both issue lists:
{
std::scoped_lock lg(allIssuesMx, openIssuesMx)
...; // 操作 allIssues 和 openIssues
}
请注意,由于类模板参数推导,您在声明 lg 时不必指定互斥锁的类型。 此示例用法等价于以下代码,从 C++11 开始可以调用:
// 锁定两个问题清单:
{
std::lock(allIssuesMx, openIssuesMx); // 避免死锁的锁
std::lock_guard<std::mutex> lg1(allIssuesMx, std::adopt_lock);
std::lock_guard<std::mutex> lg2(openIssuesMx, std::adopt_lock);
... // 同时操作allIssues和openIssues
}
因此,如果传递了多个互斥锁,则 scoped_lock 的构造函数使用可变参数便利函数 lock(…),它保证调用不会导致死锁(标准注释:“死锁避免算法,例如 因为必须使用try-and-back-off,但没有指定具体算法以避免过度约束实现”)。 如果只将一个互斥锁传递给 scoped_lock 的构造函数,它只会锁定互斥锁。 因此,在具有单个构造函数参数的 scoped_lock 中,其作用类似于 lock_guard)。 然后它甚至定义了没有为多个互斥锁定义的成员 mutex_type。1 因此,您可以将 lock_guard 的所有用法替换为 scoped_lock。 如果没有传递互斥体,则锁守卫不起作用。 请注意,您还可以采用多个锁:
// 锁定两个问题清单:
{
std::lock(allIssuesMx, openIssuesMx); // 注意:使用的死锁避免算法
std::scoped_lock lg(std::adopt_lock, allIssuesMx, openIssuesMx);
... // 同时操作allIssues和openIssues
}
然而,请注意,采用锁的构造函数现在在前面有 adopt_lock 参数。
26.1.2 std::shared_mutex
C++14添加了shared_timed_mutex来支持读/写锁,即多个线程同时读取一个值,而不时地有线程可能会更新这个值。因为在一些平台上,不支持定时锁的mutex可以更有效地实现,现在引入了shared_mutex类型(就像自C++11以来,除了std::timed_mutex之外,还有std::mutex存在)。 shared_mutex定义在头文件<shared_mutex>中,支持以下操作。
- 对于独占锁:lock(), try_lock(), unlock()
- 对于共享的读访问:lock_shared(), try_lock_shared(), unlock_shared()
- native_handle()
也就是说,与shared_times_mutex不同,它不支持try_lock_for()、try_lock_until()。try_lock_shared_for(), and try_lock_shared_until()。
使用 shared_mutex
使用shared_mutex的方法如下。假设你有一个共享vector,它通常被多个线程读取,但不时地被修改:
#include <shared_mutex>
#include <mutex>
...
std::vector<double> v; // 共享资源
std::shared_mutex vMutex; // 控制对 v 的访问(C++14 中的 shared_timed_mutex)
要进行共享读取访问(以便多个读取器不会相互阻塞),请使用 shared_lock,它是共享读取访问的锁保护(在 C++14 中引入)。 例如:
if (std::shared_lock sl(vMutex); v.size() > 0) {
... // (共享)对vector v 元素的读取访问
}
只有在排他性的写访问中,你才会使用排他性的锁防护,这可能是一个简单的lock_guard或scoped_lock(如刚刚介绍的),或者是一个复杂的unique_lock。比如说:
{
std::scoped_lock sl(vMutex);
... // 对vector 的独占写读访问
}
26.2 原子的 is_always_lock_free()
你现在可以通过一个C++库的功能来检查一个特定的原子类型是否总是可以在没有锁的情况下使用不加锁。比如说:
if constexpr(std::atomic<int>::is_always_lock_free) {
...
}
else {
...
}
如果该值为真,那么对于相应的原子类型的任何对象来说,is_lock_free()产生真:
if constexpr(atomic<T>::is_always_lock_free) {
static_assert(atomic<T>().is_lock_free()); // 从未失败
}
如果有的话,这个值与相应的宏的值相匹配,在C++17之前必须使用。 例如,如果且仅当ATOMIC_INT_LOCK_FREE产生2(代表 “总是”),那么std::atomic::is_always_lock_free()产生true。:
if constexpr(std::atomic<int>::is_always_lock_free) {
// ATOMIC_INT_LOCK_FREE == 2
...
}
else {
// ATOMIC_INT_LOCK_FREE == 0 || ATOMIC_INT_LOCK_FREE == 1
...
}
用静态成员代替宏的原因是为了有更多的类型安全,并支持在棘手的通用代码中使用这种检查(例如,使用SFINAE)。 请记住,std::atomic<>也可以用于琐碎的可复制类型。因此,你也可以检查,如果你自己的结构在原子上使用,是否需要锁。比如说:
template<auto SZ>
struct Data {
bool set;
int values[SZ];
double average;
};
if constexpr(std::atomic<Data<4>>::is_always_lock_free) {
...
}
else {
...
}
26.3 缓存线的大小
有时对于一个程序来说,处理缓存线的大小是很重要的。
- 一方面,不同线程访问的不同对象不属于同一个缓存线,这对并发性很重要。否则,当不同的线程同时访问时,同样数量的内存必须在它们之间进行同步。
- 另一方面,你的目标可能是将多个对象放在同一个缓存线中,这样访问第一个对象就可以直接访问其他对象,而不是将它们加载到缓存中。
为此,C++标准库在头文件中引入了两个内联变量。
namespace std {
inline constexpr size_t hardware_destructive_interference_size;
inline constexpr size_t hardware_constructive_interference_size;
}
这些对象有以下执行定义的值。
- hardware_destructive_interference_size是推荐的两个可能被不同线程同时访问的对象之间的最小偏移量,以避免因为同一L1缓存线受到影响而导致性能下降。
- hardware_constructive_interference_size是推荐的两个对象放在同一L1缓存行内的最大连续内存大小。
这两个值只是提示,因为理想的值可能取决于具体的架构。这些常数是编译器在处理生成的代码所支持的各种平台时所能提供的最佳值。所以,如果你知道的更多,请使用特定的值,但对于支持多种平台的代码来说,使用这些值比任何假定的固定尺寸要好。 这些值至少都是alignof(std::max_align_t)。通常情况下,值是相同的。然而,从语义上讲,它们代表了使用不同对象的不同目的,所以你应该使用它们 相应地使用它们,
如下所示:
- 如果你想通过不同的线程访问两个不同的(原子)对象。
struct Data {
alignas(std::hardware_destructive_interference_size) int valueForOneThread;
alignas(std::hardware_destructive_interference_size) int valueForAnotherThread;
};
- 如果你想通过同一个线程访问两个不同的(原子)对象。
struct Data {
int valueForOneThread;
int valueForTheSameThread;
};
// 仔细检查,由于共享缓存线,我们有最好的性能。
static_assert(sizeof(Data) <= std::hardware_constructive_interference_size);
// 确保对象被正确对齐。
alignas(sizeof(Data)) Data myDataForAThread;
26.4 后记
scoped_locks 最初是由 Mike Spertus 在 https://wg21.link/n4470 中将 lock_guard 修改为可变参数,被接受为 https://wg21.link/p0156r0。然而,因为这被证明是 ABI 破坏,新名称 scoped_lock 由 Mike Spertus 用 https://wg21.link/p0156r2 引入并最终被接受。 Mike Spertus、Walter E. Brown 和 Stephan T. Lavavej 后来通过 https://wg21.link/p0739r0 将构造函数的顺序更改为针对 C++17 的缺陷:
shared_mutex 最初是由 Howard Hinnant 在 https://wg21.link/n2406 中与 C++11 的所有其他互斥体一起提出的。然而,要让 C++ 标准化委员会相信所有提议的互斥锁都是有用的,需要时间。因此,最终接受的措辞是由 Gor Nishanov 在 https://wg21.link/n4508 中为 C++17 制定的。
std::atomic<> 静态成员 std::is_always_lock_free 由 Olivier Giroux、JF Bastien 和 Jeff Snyder 在 https://wg21.link/n4509 中首次提出。最终接受的措辞也是由 Olivier Giroux、JF Bastien 和 Jeff Snyder 在 https://wg21.link/p0152r1 中制定的。
JF Bastien 和 Olivier Giroux 在 https://wg21.link/n4523 中首次提出了硬件干扰(缓存线)大小。最终接受的措辞也是由 JF Bastien 和 Olivier Giroux 在 https://wg21.link/p0154r1 中制定的。